An intuitive picture on the central limit theorem: getting patterns from Lotto games
- Lotto games do not present any special sequences with more probabilities. However, one can obtain some patterns in an analysis of several games;
- Random variables obtained from inner random variables present simple probability distributions;
- Validity criteria for Gaussian distributions;

A lotto is a game in which the maximum prize is given to the person (or group) who correctly guesses a set of six numbers out of a range from one to sixty. Some variants exists of course, as a different range or the amount of numbers to guess, but the idea remains the same. As you certainly know the probability of winning the lotto is quite low, in the case of the variant mentioned above one has:
$P=\frac{1}{60 \times 59 \times 58 \times 57 \times 56 \times 55} \approx 2.77 \times 10^{-9} \%$
With this probability, one may guess that the price of a bet in lotto is far expensive compared to a fair value. Assuming a prize of $ \$ 12 $ millions, for instance, the fair betting price would be:
$ p= 12 \times 10^{6} \times 2.77 \times 10^{-11} \to p= \$ 33\times 10^{-5}$
This fair value is obtained the expectancy assuming the lotto a Martingale process. Clearly, someone who bets $ \$ 2.50$ in a lotto game is paying around 7500 times more than a fair value.
First, it is worth reinforcing that in principle any sequence in the lotto presents the exact same probability! There are no special sequences. However, it is possible to get some interesting patterns of high statistical importance, considering large sets of sequence. In fact, this study exemplifies some uses of the Central limit theorem which is the main underlying theorem for the validity of the Gaussian distribution.
It is worth reinforcing that in principle any sequence in the lotto presents the exact same probability! There are no special sequences. However, it is possible to get some interesting patterns of high statistical importance, considering large sets of sequence.
Consider next we generate different random sequences for the Lotto game describe above, then we sum the elements of each of the sequences: $ \sum_{i}^{6}[X_i]_j$, we then plot the normalized histogram. At first, suppose we generate only 20 games, that is $j=1,2...,20$:
 |
| Histogram with only 20 games. |
The horizontal axis shows the value of the sum of the six elements of the sequences whereas the vertical axis shows the corresponding normalized frequencies. The figure shows a distribution approximately uniform, indicating that no pattern is followed in this case. The line is obtained considering a kernel based on Gaussian probabilities.
A situation significantly different appears in the histogram obtained increasing the number of games to 200:
One can now observe a bias to the central values of the histogram becoming clearer. Following the same idea above, we present the results for 50000 games:
Now the pattern is clear. The result obtained with 50000 games presents a sharp Gaussian behavior with slight deviations close to the peak value. In probability theory, this result is known from the well-established Central Limit Theorem (CLT). This theorem says that the in some cases the appropriately normalized sum of independent random variables tends to a normal distribution, even when these variables do not present Gaussian distribution. This is exactly what we observe in the example above. In fact, in a lotto game the numbers have uniform distribution, that is, simply a line from 1 to 60.
The example used so far using Lotto games is a suitable proxy for a very important result in statistical analysis. These results exemplify why many phenomena and statistical experiments presents a Gaussian distribution. Each value of the variable used to obtain the Gaussian distribution is a collective response of several random (inner) variables. Mathematically, this can be written as:
In the example of the distribution given above, each value inserted in the figure comes from the sum of a sequence of the Lotto number acting as the (inner) variables.
In the example below, we consider a sequence of five random variables with uniform distribution from 1 to 60, and a sixth random variable whose variation is from 1 to 300. In fact, the distribution is significantly different from a Gaussian:


 The last figure can be fitted with a Weibull distribution:
The last figure can be fitted with a Weibull distribution:
I hope you enjoyed the post. May the Force be with you.
#=================================
Diogo de Moura Pedroso
LinkedIn: www.linkedin.com/in/diogomourapedroso
A situation significantly different appears in the histogram obtained increasing the number of games to 200:
 |
| Histogram with 200 games. |
 |
| Histogram with 50000 games. |
The example used so far using Lotto games is a suitable proxy for a very important result in statistical analysis. These results exemplify why many phenomena and statistical experiments presents a Gaussian distribution. Each value of the variable used to obtain the Gaussian distribution is a collective response of several random (inner) variables. Mathematically, this can be written as:
$\lim_{n \to \infty} \frac{1}{s_n} \sum_{i=1}^{n}[X_i - \mu_i] = N(0,1)$
where $s_{n}^{2}= \sum_{i=1}^{n}\sigma_i^2$, $\mu_i$ is the average of each element of the sequence $\{X_0,X_1, ...,X_n\}$, and $\sigma_i$ is the standard deviation.In the example of the distribution given above, each value inserted in the figure comes from the sum of a sequence of the Lotto number acting as the (inner) variables.
Influence of the number of (inner) variables
It is also worth to mentioning that the number of variables composing the sequences also influences the obtained pattern. In fact, the use of larger sequences (number of variables) requires a lower number of games to obtain a reasonable Gaussian shape. In order to illustrate the influence of the size of the sequence, the first below is obtained using a sequence of two random number, whereas the second uses sequences of 50 numbers. The number of games for both figures is 1000. |
| Games: 1000 / sequence: 2 |
 |
| Games: 1000 / sequence: 50 |
Analysis of the variance: Lindeberg´s condition
A condition for observing a Gaussian distribution in the examples above relies on the fact that all random variables in the sequence present the same variance. In the case that the variance of one of these variables is much larger than the others, one would not observe a Gaussian distribution. This is the Lindeberg´s condition. Financial markets, for instance, does not meet the Lindeberg´s condition all the time, specially when big players make their movements, changing considerably the current prices.In the example below, we consider a sequence of five random variables with uniform distribution from 1 to 60, and a sixth random variable whose variation is from 1 to 300. In fact, the distribution is significantly different from a Gaussian:

What if...?
A question rises: is it possible to get similar patterns using other operations than a simple sum? The answer is yes! Consider, for instance, the sum of $cos(X_i)$ and the sum of $log(X_i)$.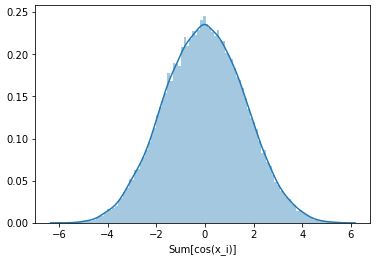

$f(x, \lambda, k)=\frac{k}{\lambda}(\frac{x}{\lambda})^{k-1}e^{-(x/\lambda)^k}$ for $x \ geq 0$
where $k$ is a shape parameter and $\lambda$ is a scale parameter of the distribution.
I hope you enjoyed the post. May the Force be with you.
#=================================
Diogo de Moura Pedroso
LinkedIn: www.linkedin.com/in/diogomourapedroso


Comments
Post a Comment